All parallel libraries rely on a scheduler to organize and order the execution of tasks and threads,
and TPL is no exception. This section is a behind-the-scenes look at
the .NET Framework 4 implementation of task scheduling. The material in
this section can help you understand the performance characteristics
that you’ll observe when using TPL and PLINQ. Be aware that the
scheduling algorithms described here represent an implementation
choice. They aren’t constraints imposed by TPL itself, and future
versions of .NET might optimize task execution differently.
Note:
The behind-the-scenes behavior
described in this section applies to .NET Framework 4. There’s no
guarantee that future releases of the runtime or the framework won’t
behave differently.
In .NET Framework 4,
the default task scheduler is tightly integrated with the thread pool.
If you use the default task scheduler, the worker threads that execute parallel tasks are managed by the .NET ThreadPool
class. Generally, there are at least as many worker threads as cores on
your computer. When there are more tasks than available worker threads,
some tasks will be queued and wait until the thread pool provides an
available worker thread.
An example of this approach is the thread pool’s QueueUser WorkItem
method. In fact, you can think of the default task scheduler as an
improved thread pool where work items return a handle that a thread can
use as a wait condition, and where unhandled task exceptions are
forwarded to the wait context. The handles to the work items are called
tasks, and the wait condition occurs when you call the task’s Wait
method. In addition to these enhancements, the default thread scheduler
is capable of better performance than the thread pool alone as the
number of cores increases. Here’s how this works.
1. The Thread Pool
In its simplest form, a thread
pool consists of a global queue of pending work items and a set of
threads that process the work items, usually on a first-in first-out
(FIFO) basis. This is shown in Figure 1.
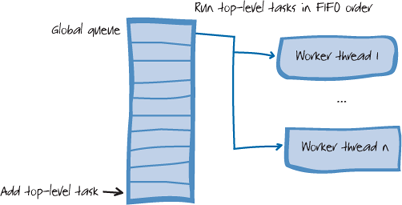
Thread
pools have problems scaling to large numbers of cores. The main reason
is that the thread pool has a single, global work queue. Each end of
the global queue can be accessed by only one thread at a time, and this
can become a bottleneck. When there are only a few, coarse-grained work
items and a limited number of cores, the synchronization overhead of a
global queue (that is, the cost of ensuring that only one thread at a
time has access) is small. For example, the overhead is negligible when
the number of cores is four or fewer and when each work item takes many
thousands of processor cycles. However, as the number of cores
increases and the amount of work that you want to do in each work item
decreases (due to the finer-grained parallelism
that is needed to exploit more of the cores), the synchronization cost
of the traditional thread pool design begins to dominate.
Synchronization is an
umbrella term that includes many techniques for coordinating the
activities of multi-threaded applications. Locks are a familiar example
of a synchronization technique. Threads use locks to make sure that
they don’t try to modify a location of memory at the same time as
another thread. All types of synchronization have the potential of
causing a thread to block (that is, to do no work) until a condition is
met.
Tasks in .NET are designed to
scale to large numbers of cores. They are also lightweight enough to
perform very small units of work, in the hundreds or low thousands of
CPU cycles. In .NET, it’s possible for an application to run
efficiently with millions of tasks. To handle this kind of scale, a
more decentralized approach to scheduling than one that uses a single
global queue is needed.
2. Decentralized Scheduling Techniques
The .NET Framework provides local task
queues for each worker thread in the thread pool. Local task queues
distribute the responsibility for queue management and avoid much of
the serial access required by a global queue of work items. Giving
different parts of the application their own work queues helps avoid a
central bottleneck. This is shown Figure 2.
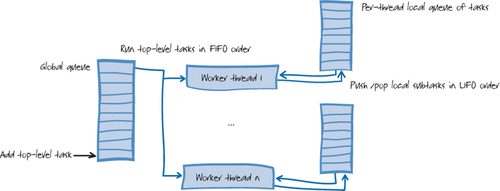
You can see that there are as
many task queues as there are worker threads, plus one global queue.
All of these queues operate concurrently. The basic idea is that when a
new task needs to be added, it can sometimes be added to a thread-local
queue instead of to the global queue, and when a thread is ready for a
new task to run, it can sometimes find one waiting in its local queue
instead of having to go to the global queue. Of course, any work that
comes from a thread that is not one of the thread pool’s worker threads
still has to be placed on the global queue, which always incurs heavier
synchronization costs than adding to a local queue.
In the typical case,
accessing the local queue needs only very limited synchronization.
Items can be locally added and removed very quickly. The reason for
this efficiency is that the local queues are implemented using a
special concurrent data structure known as a work-stealing queue. A
work-stealing queue is a double-ended queue that has a private end and
a public end. The queue allows lock-free pushes and pops from the
private end but requires costlier synchronization for operations at the
public end. When the length of the queue is small, synchronization is
required from both ends due to the locking strategy used by the
implementation.
Moving to a
distributed scheduling approach makes the order of task execution less
predictable than with a single global queue. Although the global queue
executes work in FIFO order, the local work-stealing queues use LIFO
order to avoid synchronization costs. However, the overall throughput
is likely to be better because a thread only uses the relatively more
expensive global queue when it runs out of work from its local queue.
3. Work Stealing
What happens when a thread’s
local work queue is empty and the global queue is also empty? There
still may be work on the local queues of other worker threads. This is
where work stealing comes into play. This is shown Figure 3.

The diagram shows that when
a thread has no items in its local queue, and there are also no items
in the global queue, the system “steals” work from the local queue of
one of the other worker threads. To minimize the amount of
synchronization, the system takes the task from the public end of the
second thread’s work-stealing queue. This means that, unless the queue
is very short, the second thread can continue to push and pop from the
private end of its local queue with minimal overhead for
synchronization.
This mix of LIFO and FIFO
ordering has other interesting benefits that arise from the work
distribution patterns of typical applications. It turns out that LIFO
order makes sense for local queues because it reduces the likelihood of
a cache miss. Something that has just been placed in a work queue has a
good chance of referencing objects that are still present in the
system’s memory caches. One way to take advantage of the cache is by
prioritizing recently added tasks.
Many parallel algorithms have a divide-and-conquer approach similar to recursion.
The largest chunks of work tend to get pushed onto the queue before
smaller subtasks. With FIFO ordering, these larger chunks are the first
to be removed by other threads. Transferring a larger task
to another thread reduces the need for stealing additional tasks in the
future. As one of these larger tasks executes, it pushes and pops its
subtasks in the new thread’s local queue. This is a very effi-cient way to schedule these kinds of tasks.
4. Top-Level Tasks in the Global Queue
Tasks are placed in the global queue whenever a task factory method is invoked from a thread that is not one of the thread pool worker threads. (Of course, the factory method must be allowed to use the default
task scheduler for this to be true. The information in this section
applies only to tasks managed by the default task scheduler.)
You can also force the default task scheduler to place a task in the global queue by passing the task creation option PreferFairness to the factory method.
In this book, tasks in the
global queue are called top-level tasks. Top-level tasks have
approximately the same performance characteristics as work items that
have been created with the thread pool’s QueueUserWorkItem method.
5. Subtasks in a Local Queue
When one of the task
factory methods is called from within a thread pool worker thread, the
default task scheduler places the new task in that thread’s local task
queue. This is a faster operation than placing it in the global queue.
The default task
scheduler assumes that minimizing the worst-case latency for subtasks
isn’t important. Instead, its goal is to optimize overall system
throughput. This makes sense if you believe that any time you create a
task from within another task or from within a thread pool work item,
you are performing an operation that is part of some larger computation
(such as a top-level task). In this case, the only latency that matters
is that of the top-level task. Therefore, the default task scheduler
doesn’t care about FIFO ordering of subtasks. Although these
assumptions don’t hold in all cases, understanding them will help you
use the features of the default task scheduler in the most efficient
way for your application.
In this book, tasks in a
local queue are known as subtasks. The motivation for this term is that
most tasks that end up in a local queue are created while executing the
user delegate of some other task.
6. Inlined Execution of Suntasks
It’s often the case that a
task must wait for a second task to complete before the first task can
continue. If the second task hasn’t begun to execute, you might imagine
that the thread that is executing the first task blocks until the
second task is eventually allowed to run and complete. An unlucky queue
position for the second task can make this an arbitrarily long wait,
and in extreme cases can even result in deadlock if all other worker
threads are busy.
Fortunately, the TPL can detect whether the second task has begun to execute. If the second task is not yet running, the default task scheduler can sometimes execute it immediately in the first task’s thread context. This technique, known as inlined execution,
enables the reuse of a thread that would otherwise be blocked. It also
eliminates the possibility of deadlock due to thread starvation. A nice
side effect is that inline execution can reduce overall latency by
acting as a scheduling short cut for urgent tasks.
The default task scheduler in .NET Framework 4 inlines a pending subtask if Task.Wait or Task.WaitAll
is called from within the worker thread whose local queue contains that
subtask. Inlining also applies to tasks created by methods of the Parallel
class if these methods are called from within a worker thread. In other
words, a thread pool worker thread can perform inline execution of
tasks that it created. Top-level tasks in the global queue are never
eligible to be inlined, and tasks created with the LongRunning task creation option do not inline other tasks.
The default task
scheduler’s policy for inline execution was motivated by the
synchronization requirements of the work-stealing queues. Removing or
marking a task in another local queue as “processed” would require
additional, expensive cross-thread synchronization. Also, it turns out
that typical applications almost never need cross-thread inlining. The
most common coding patterns result in subtasks that reside in the local
queue of the thread that executes the parent task.
7. Thread Injection
The .NET thread pool
automatically manages the number of worker threads in the pool. It adds
and removes threads according to built-in heuristics. The .NET thread
pool has two main mechanisms for injecting threads: a
starvation-avoidance mechanism that adds worker threads if it sees no
progress being made on queued items and a hill-climbing heuristic that
tries to maximize throughput while using as few threads as possible.
The goal of starvation
avoidance is to prevent deadlock. This kind of deadlock can occur when
a worker thread waits for a synchronization event that can only be
satisfied by a work item that is still pending in the thread pool’s
global or local queues. If there were a fixed number of worker threads,
and all of those threads were similarly blocked, the system would be
unable to ever make further progress. Adding a new worker thread
resolves the problem.
A goal of the hill-climbing
heuristic is to improve the utilization of cores when threads are
blocked by I/O or other wait conditions that stall the processor. By
default, the managed thread pool has one worker thread per core. If one
of these worker threads becomes blocked, there’s a chance that a core
might be underutilized, depending on the computer’s overall workload.
The thread
injection logic doesn’t distinguish between a thread that’s blocked and
a thread that’s performing a lengthy, processor-intensive operation.
Therefore, whenever the thread pool’s global or local queues contain
pending work items, active work items that take a long time to run
(more than a half second) can trigger the creation of new thread pool
worker threads.
The .NET thread pool
has an opportunity to inject threads every time a work item completes
or at 500 millisecond intervals, whichever is shorter. The thread pool
uses this opportunity to try adding threads (or taking them away),
guided by feedback from previous changes in the thread count. If adding
threads seems to be helping throughput, the thread pool adds more;
otherwise, it reduces the number of worker threads. This technique is
called the hill-climbing heuristic.
Therefore, one reason to
keep individual tasks short is to avoid “starvation detection,” but
another reason to keep them short is to give the thread pool more
opportunities to improve throughput by adjusting the thread count. The
shorter the duration of individual tasks, the more often the thread
pool can measure throughput and adjust the thread count accordingly.
To make this concrete,
consider an extreme example. Suppose that you have a complex financial
simulation with 500 processor-intensive operations, each one of which
takes ten minutes on average to complete. If you create top-level tasks
in the global queue for each of these operations, you will find that
after about five minutes the thread pool will grow to 500 worker
threads. The reason is that the thread pool sees all of the tasks as
blocked and begins to add new threads at the rate of approximately two
threads per second.
What’s wrong with 500
worker threads? In principle, nothing, if you have 500 cores for them
to use and vast amounts of system memory. In fact, this is the
long-term vision of parallel computing. However, if you don’t
have that many cores on your computer, you are in a situation where
many threads are competing for time slices. This situation is known as
processor oversubscription. Allowing many processor-intensive threads
to compete for time on a single core adds context switching overhead
that can severely reduce overall system throughput. Even if you don’t
run out of memory, performance in this situation can be much, much
worse than in sequential computation. (Each context switch takes
between 6,000 and 8,000 processor cycles.) The cost of context
switching is not the only source of overhead. A managed thread in .NET
consumes roughly a megabyte of stack space, whether or not that space
is used for currently executing functions. It takes about 200,000 CPU
cycles to create a new thread, and about 100,000 cycles to retire a
thread. These are expensive operations.
As long as your tasks
don’t each take minutes, the thread pool’s hill-climbing algorithm will
eventually realize it has too many threads and cut back on its own
accord. However, if you do have tasks that occupy a worker thread for
many seconds or minutes or hours, that will throw off the thread pool’s
heuristics, and at that point you should consider an alternative.
The first option is to
decompose your application into shorter tasks that complete fast enough
for the thread pool to successfully control the number of threads for
optimal throughput.
A second possibility is to implement your own task scheduler object that does not perform thread
injection. If your tasks are of long duration, you don’t need a highly
optimized task scheduler because the cost of scheduling will be
negligible compared to the execution time of the task. MSDN® developer
program has an example of a simple task scheduler implementation that
limits the maximum degree of concurrency.
As a last resort, you can use the SetMaxThreads method to configure the ThreadPool class with an upper limit for the number of worker threads, usually equal to the number of cores (this is the Environment.ProcessorCount property). This upper limit applies for the entire process, including all AppDomains.
Note:
The SetMaxThreads
method can cause deadlock if thread pool worker threads are waiting for
scheduled work items to run. Use it with extreme caution.
8. Bypassing The Thread Pool
If you don’t want a task to use
a worker thread form the thread pool, you can create a new thread for
its dedicated use. The new thread will not be a thread pool worker
thread. To do this, include the Long Running
task creation option as an argument to one of the task factory methods.
The option is mostly used for tasks with long I/O-related wait
conditions and for tasks that act as background helpers.
A disadvantage of bypassing the thread pool is that, unlike a worker thread that is created by the thread pool’s thread injection logic, a thread created with the LongRunning option cannot use inline execution for its subtasks.